分析短信聊天记录
这两天编了个 Python 程序分析自己和别人的短信聊天记录,先把结果放出来。
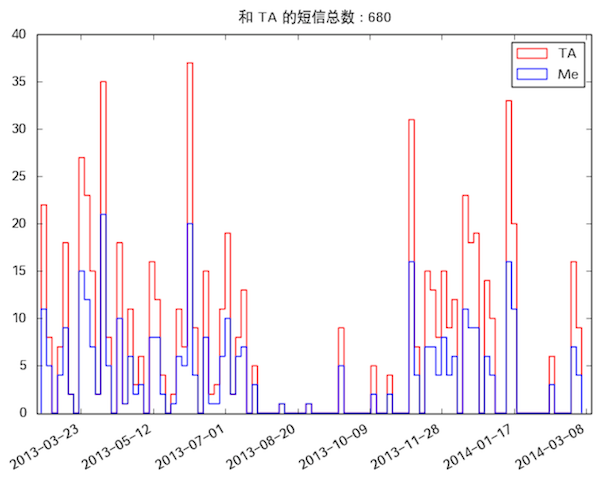
所有和某人的短信直方图。我这里随便选了个人,各位不要猜是谁。
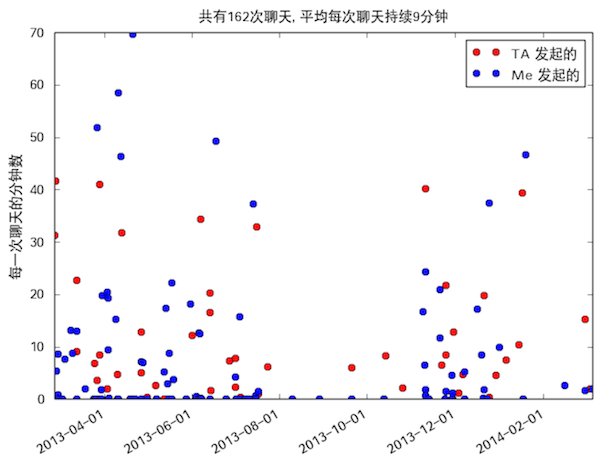
每次聊天(包含多条短信,根据时间间隔判断是否属于同一次聊天)的时间图。
每次聊天(包含多条短信,根据时间间隔判断是否属于同一次聊天)的短信次数图。
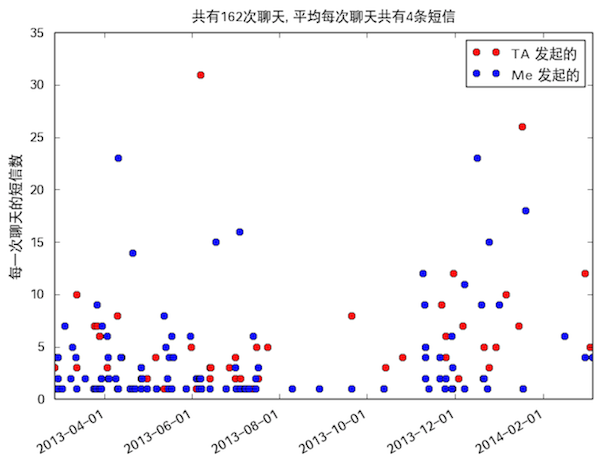
是不是发现我加错技能点了?下面开始细讲。
获取短信记录
首先你手机上需要还存有所有的短信记录,反正我是没有,但是我有 SMS Backup+ 这个手机上的应用可以把每次我收到和发送的短信信息上传到 GMail 里面去。具体的话它会建立一个标签 SMS 然后所有的短信记录以邮件的方式储存在邮箱里。所有如果你之前没有安装这个应用,但是想分析的话,第一步就是下载这个应用然后让它把你所有的短信记录存到邮箱里(当然你可以选择其他应用然后把短信记录以其他形式输出,不过由于我一直用的是 SMS Backup+,而且手机里已经没有所有短信记录了…)
然后就是下载这些短信邮件了,我们需要用到 Google Takeout 把所有标签为 SMS 的邮件下载到电脑中,结果格式为 MBOX,我查了下,貌似是个通用的邮件格式,我苹果机里的 Mail 可以输入。
输入到 Python 中
现在就要去分析这些短信了,反正我是用的杀人放火都可以用的 Python。不得不说 Python 真的是蛇里面的一条好蛇,人人都喜欢,所以各种 Librairies 都有。我立马就找到了一个叫 mailbox 的 Package,它允许我读取 MBOX 格式的文件,并建立一个这些邮件的数据库。
mbox = mailbox.mbox('SMS.mbox') # 包含所有由 SMS Backup+ 上传的短信记录
mbox 是一个 Python 列表,里面每个元素都是一条短信,一条短信包含主题、发送人、收取人、发送时间等属性。我只关心发送时间和这条短信是谁发给谁的信息,所以我只会用到
mbox[0]['Subject'] 为了知道这条短信是和谁发的或者是谁发来的
mbox[0]['Date] 为了知道这条短信的发送时间
mbox[0]['From] 这条短信是谁发的
这三个属性。因为 SMS Backup+ 插件会把邮件的主题改为 SMS avec XX 而 XX 就是那个人在你 GMail 中的名字。
我到底要干嘛和一点数学
先打住一下,想想我具体想分析些什么。先从简单的说起,我想知道和某人一共产生的短信数,我发了几条,TA 发了几条。不仅仅这三个数字,我想知道我和 TA 的短信交流在时间上的分布:比如说去年3月份一共有几条短信,其中几条我发的,几条 TA 发的之类的,这个就是我第一张图,只不过我细化了很多,直方图的每一个 Bar 不是一个月,而是某几天…
其次我想知道到底每次短信聊天是谁先发起的…大家都有这个经历,你先发了一条或者 TA 先发了一条,然后你们就开始短信聊天了…每一次聊天可能包含多条短信交换,所以第一步就要在所有短信集合 \(S\) 中做一个划分 \(P\) 使得
\[\cup_{c\in P}c=S\text{ and }c_i\cap c_j=\emptyset\text{ for $i\neq j$}\]大致就是说在 \(P\) 集合中,每个元素都是一次短信聊天 \(c\),而 \(c\) 本身可以包含很多条短信,这些短信交换构成了一次短信聊天。短信聊天 \(c_1\) 和 \(c_2\) 不能包含相同的一条短信,否则其实这两次聊天应该算作一起的…哈哈,这些都是集合论的基本知识啊…好吧分划和等价关系这个是有点难。
接下去我就要具体去做这个划分了…其实很简单,怎么认为这些条短信属于同一次聊天呢,我把这些短信从最老到新(时间上)排列好,如果后一条短信发送时间与上一条的间隔少于某个限额,比如说1小时(1小时!但就是有人会1小时后才回复你短信啊),那么认为后一条短信和前一条短信有关,算作是属于同一次聊天…然后我们以此类推,分析再下一条短信与之前一条短信的时间差…然后判断。
有了所有聊天记录后,我们就可以去分析了…比如这次聊天包含多少次短信交流,比如这次聊天持续了多少时间…我现在觉得聊天时间这个指标不好,因为就像刚刚说的,如果 TA 1小时后(就小于1小时一点点…)才回复我,那根据指标也算作同一次聊天,但我们绝对没有聊了1小时吧…所以还是聊天一共产生的短信数比较好。
具体 Python 实现
其实没啥好讲的,因为都是些琐碎的编程问题。比如说对于中文邮件,其主题变成了一个64位可以转换成 UTF-8 编码的字符串,所以需要做
import base64
prefix = '=?UTF-8?B?' # 为了转换编码 无需改变
suffix = '?=' # 为了转换编码 无需改变
sub = m['Subject']
if sub.startswith('=?UTF-8'):
sub = sub[len(prefix):len(sub)-len(suffix)]
sub = base64.b64decode(sub)
sub = unicode(sub, 'utf-8')
将某些主题转换成 UTF-8,然后再去判断到底是和谁的短信。下面把源代码放出来,你需要安装 Python 2.7 和一些科学计算的插件比如 numpy、scipy 和绘图包 matplotlib。你需要改的除了 me 就是 TA,它是一个列表,包含了所有 TA 的 UTF-8 名字…因为我有一段时间用过中文名字的联系人,后来又不用了…所以我需要在列表中包含中文名和拼音防止漏短信,我还加上了 TA 的邮箱,这是因为 mbox[0]['From'] 是发送人,然后除了有名字外必然还有邮箱,由于有时候会有编码问题,所以用邮箱是最保险的。最后,Happy Pythoning!
最后说句,本来以为我发 TA 的短信比 TA 发我的短信肯定多很多,结果也没多多少…发起聊天的的确我比较多…So what…
留下评论